Neural Networks
From Biological Inspiration to Mathematical Foundation
Dr. Dhaval Patel • 2025
🎯 Complete Learning Journey
Here, we will learn from a neural network from beginner to someone who truly understands it.
🧠 Motivation
Neural networks power everything from your smartphone's camera to autonomous vehicles. Understanding them isn't just academic—it's essential for anyone working in modern technology.
- Fundamental Challenge: Why traditional programming fails at pattern recognition
- Biological Inspiration: How brain-like structures solve impossible problems
- Mathematical Foundation: The elegant math that makes it all work
- Practical Implementation: From theory to working code
- Advanced Concepts: Weight optimization and learning algorithms
- Real-World Applications: How these concepts scale to modern AI
Part I
The Fundamental Challenge
The Human-Computer Paradox

🤔 The Paradox
For Humans: Instant, effortless, automatic recognition across infinite variations.
For Computers: Each pixel must be analyzed, patterns must be hard-coded, exceptions must be manually programmed.
Try writing an if-statement to recognize ANY handwritten "3" - you'll quickly realize it's impossible!
Traditional Programming vs Neural Networks
Traditional Programming
Rule-Based Approach:
- Programmer writes explicit rules
- If-then-else logic chains
- Every scenario must be anticipated
- Breaks down with complexity
- Cannot handle exceptions gracefully
// What goes here for "3"?
}
Neural Networks
Learning-Based Approach:
- Network learns patterns from examples
- Automatic feature extraction
- Handles unseen variations
- Scales with data complexity
- Graceful degradation
"This is a 3", "This is a 3"...
Network learns to recognize ANY 3!
Part II
Understanding Neurons: The Building Blocks
🧠 Introduction: The "Neuron"
Let's understand what a neural network neuron actually is:
That's it. No complex biology, no mysterious processes. Just a number.
🔢 The "Activation" Concept
This number is called the neuron's activation:
- 0.0: Neuron is "off" or inactive
- 1.0: Neuron is "fully activated" or "fired up"
- 0.3, 0.7, etc.: Partial activation levels
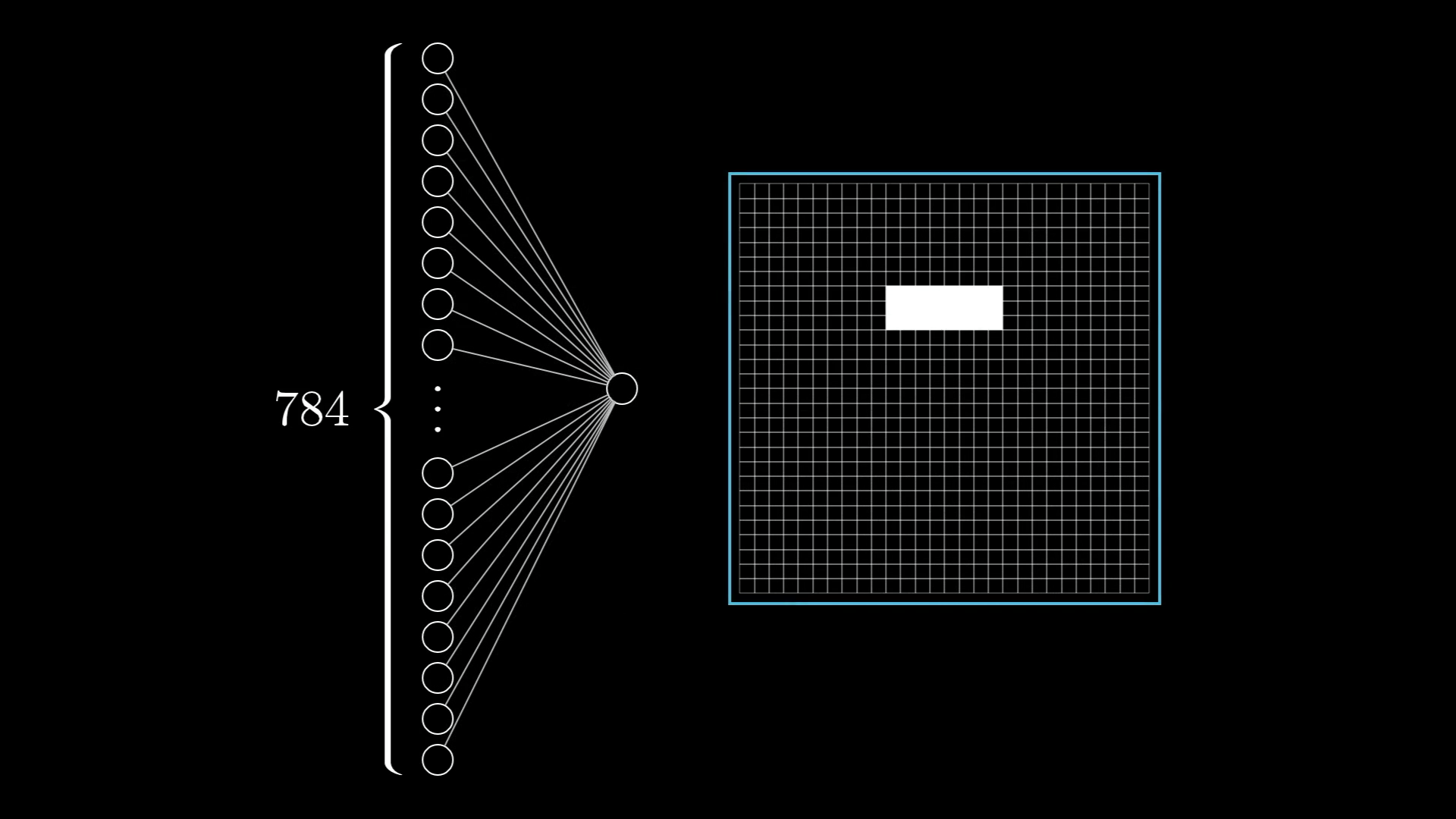
Input Layer: Converting Reality to Numbers
📊 The Conversion Process
Image → Numbers:
- 28×28 pixel image = 784 total pixels
- Each pixel: brightness value 0.0-1.0
- Black pixels = 0.0
- White pixels = 1.0
- Gray pixels = values between
🔄 Information Encoding
Every piece of information must be converted to numbers between 0 and 1 to be processed by a neural network.
The Input Layer in Action
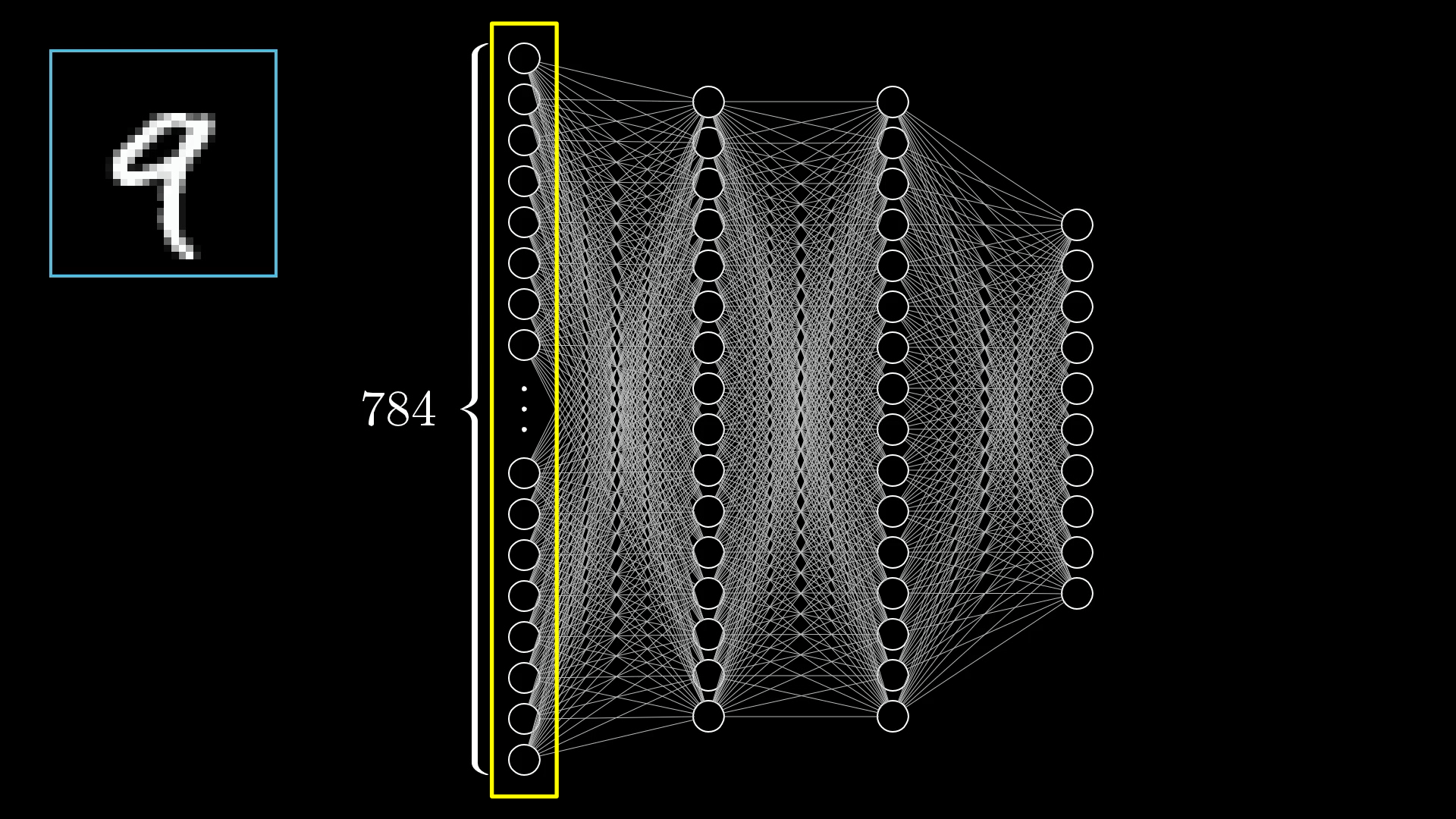
🔍 Layer Breakdown
Input Layer Structure:
- 784 neurons total
- Each neuron = one pixel
- Organized in conceptual 28×28 grid
- Values fed simultaneously
Output Layer: Making Predictions
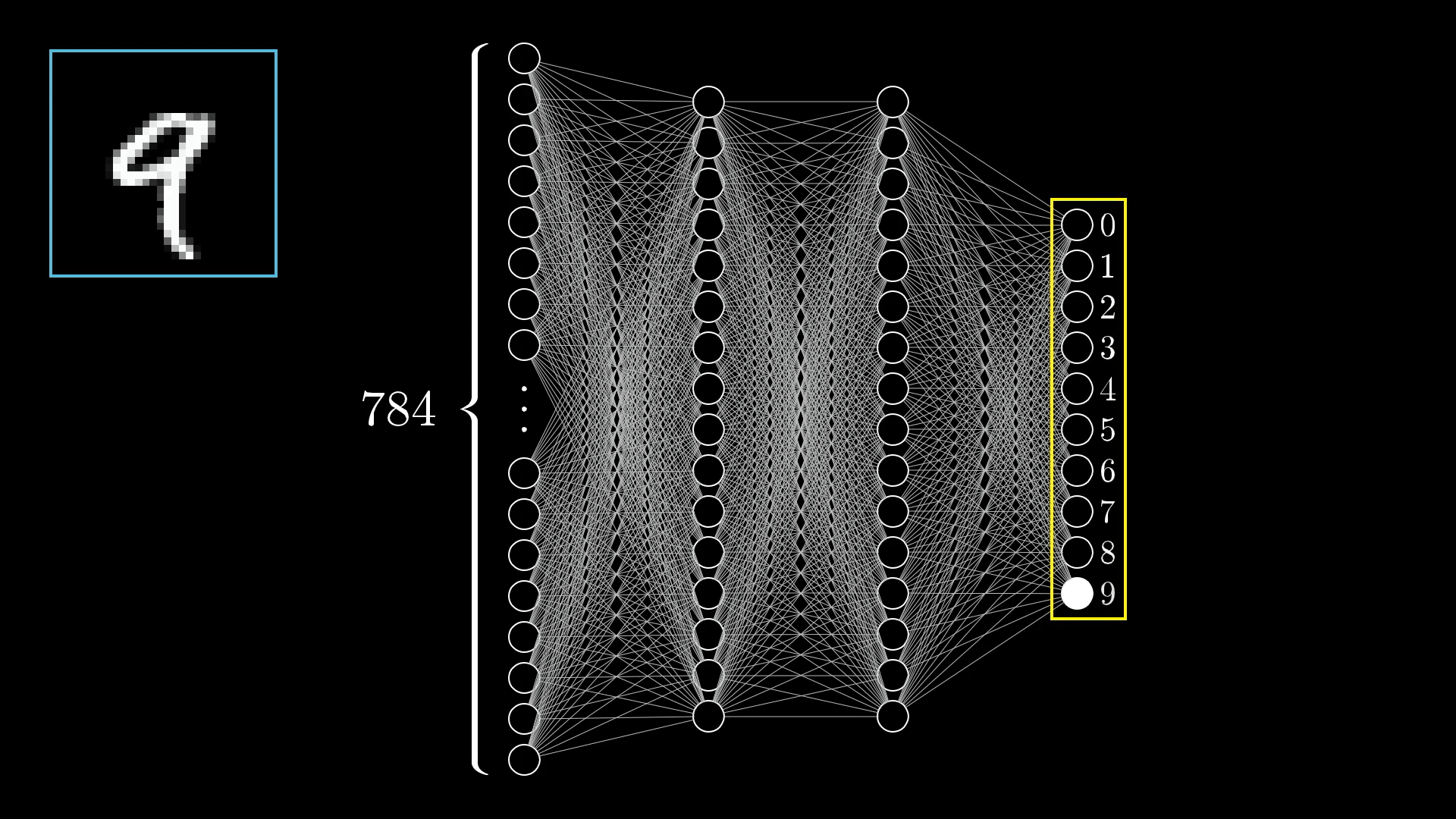
🎯 Prediction Mechanism
10 Output Neurons:
- Neuron 0: "How much does this look like 0?"
- Neuron 1: "How much does this look like 1?"
- ...
- Neuron 9: "How much does this look like 9?"
When Networks Are Uncertain
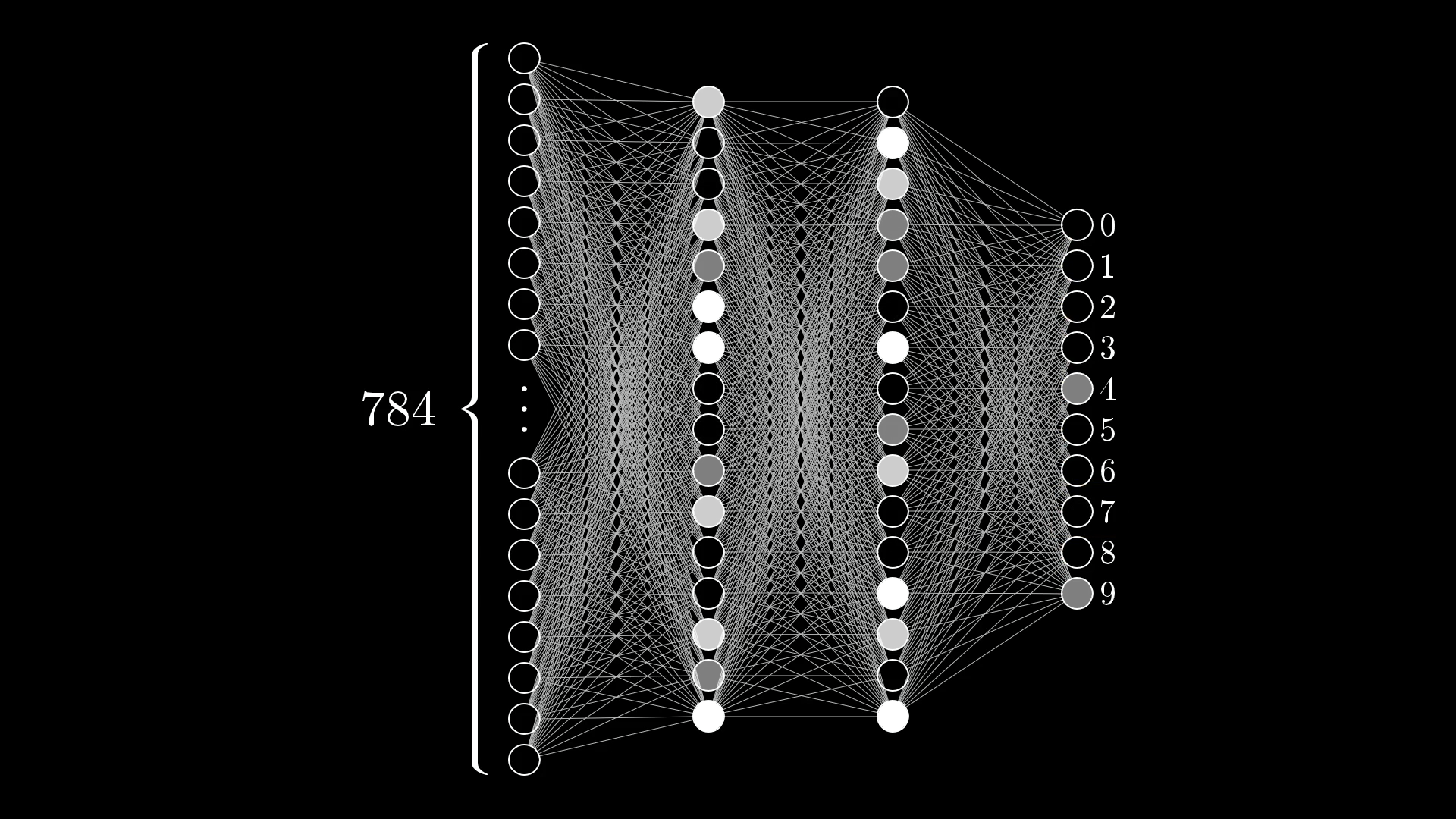
🤔 Interpreting Uncertainty
What This Tells Us:
- Network is torn between "4" and "9"
- Both neurons highly activated
- Other digits have low confidence
- This reflects realistic ambiguity!
🧠 Human-Like Reasoning
Just like humans might be unsure between similar-looking digits, networks can express this uncertainty through activation patterns.
Part III
The Hidden Layers: Where Magic Happens
The Great Mystery: Hidden Layers
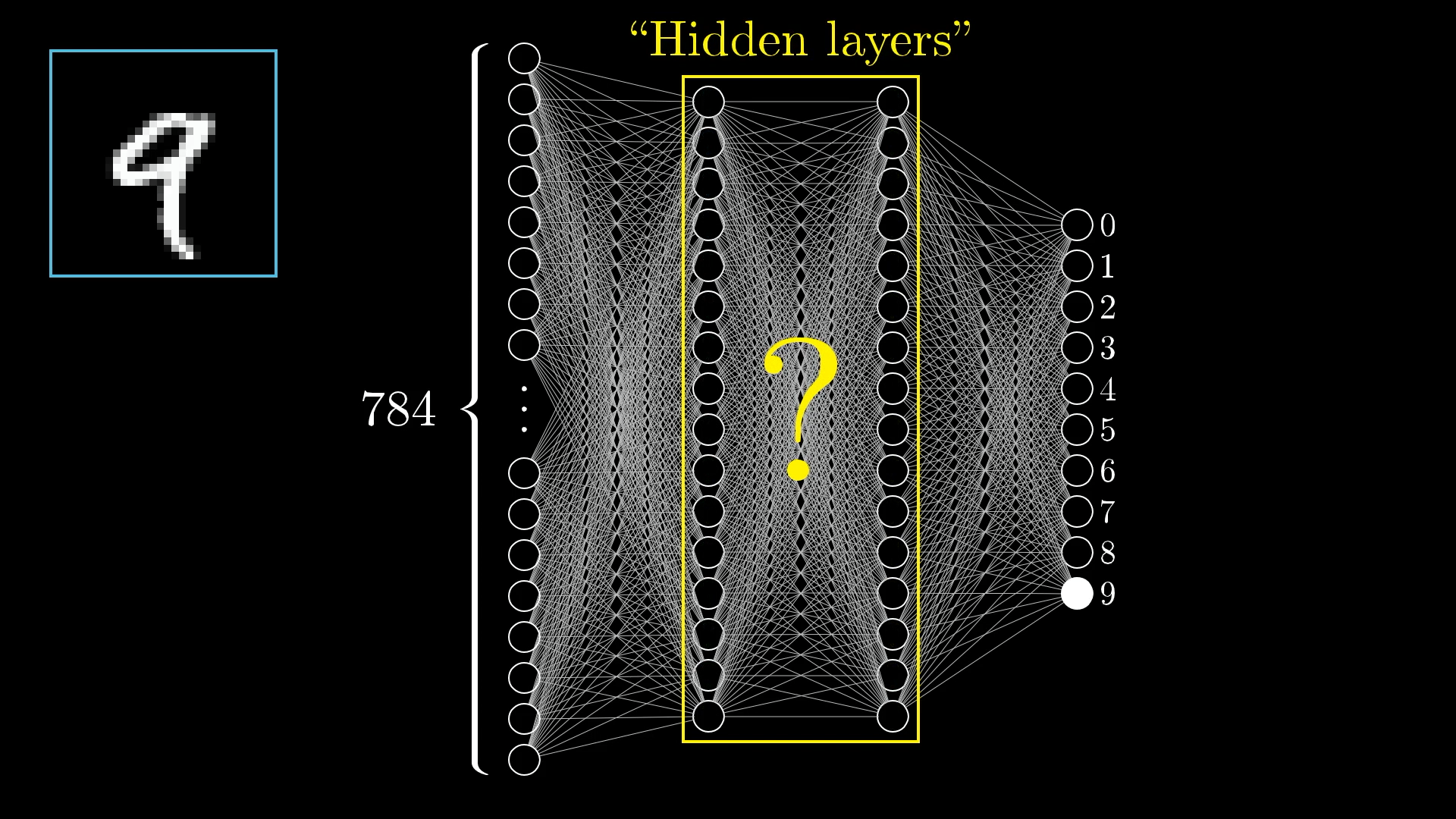
❓ The Big Questions
- What are these layers actually doing?
- How do they transform 784 numbers into 10 predictions?
- Why not connect input directly to output?
🔍 The Hypothesis
Hidden layers learn to detect increasingly complex features, building up from simple to sophisticated patterns.
The Hierarchical Learning Hypothesis
🏗️ Layer 1: Edge Detection
The first hidden layer learns to detect basic edges and simple patterns.
- Horizontal lines
- Vertical lines
- Diagonal edges
- Simple curves
🧩 Layer 2: Pattern Assembly
The second hidden layer combines edges into meaningful patterns.
- Loops (for 0, 6, 8, 9)
- Lines (for 1, 4, 7)
- Curves (for 2, 3, 5)
- Intersections
Layer 1: Edge Detection in Action

🔍 Breaking Down Complexity
Digit "0" Analysis:
- Top curve (red box)
- Right edge (blue box)
- Bottom curve (green box)
- Left edge (yellow box)
🎯 The Insight
Complex shapes are combinations of simpler edges. If we can detect edges, we can detect shapes!
More Edge Detection Examples

🔍 Digit "1" Analysis
Simpler Pattern:
- Main vertical line (blue)
- Top angle (red)
- Base extension (yellow)
Beyond Digits: Universal Pattern Recognition

🌍 Universal Applications
Edge Detection Works For:
- Animal recognition
- Face detection
- Medical imaging
- Satellite imagery
- Quality control
🚀 Powerful Principle
The same hierarchical approach works across completely different domains!
Hierarchical Processing in Other Domains
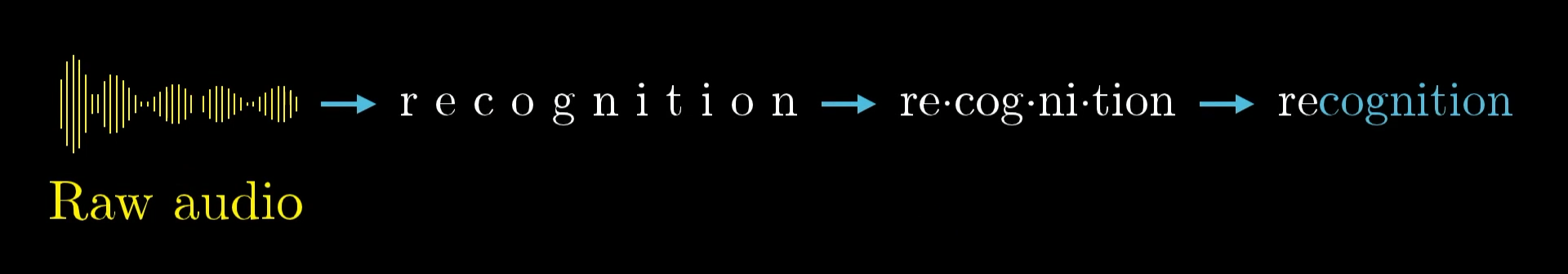
🎵 Speech Recognition Hierarchy
Layer by Layer:
- Layer 1: Raw audio → Basic sounds
- Layer 2: Sounds → Phonemes
- Layer 3: Phonemes → Syllables
- Layer 4: Syllables → Words
- Layer 5: Words → Meaning
Part IV
The Mathematics: How Information Flows
🔗 Understanding Weights: The Connection Strength
Now we get to the heart of how neural networks actually work. The magic lies in the weights.
🧠 The Core Concept
A weight is simply a number that determines how much influence one neuron has on another. That's it.
Here's how it works:
- Positive weight: "When the first neuron is active, the second should be active too"
- Negative weight: "When the first neuron is active, the second should be inactive"
- Zero weight: "These neurons don't influence each other"
- Large magnitude: Strong influence (positive or negative)
- Small magnitude: Weak influence
Weights in Action: Detecting a Specific Edge
🎯 The Goal
We want this neuron to detect this specific edge pattern.
Strategy:
- High positive weights where we want bright pixels
- High negative weights where we want dark pixels
- Zero weights where we don't care
💡 The Insight
By carefully choosing 784 weights, we can make this neuron respond strongly to our desired pattern and weakly to others!
Visualizing Weights: The Complete Picture
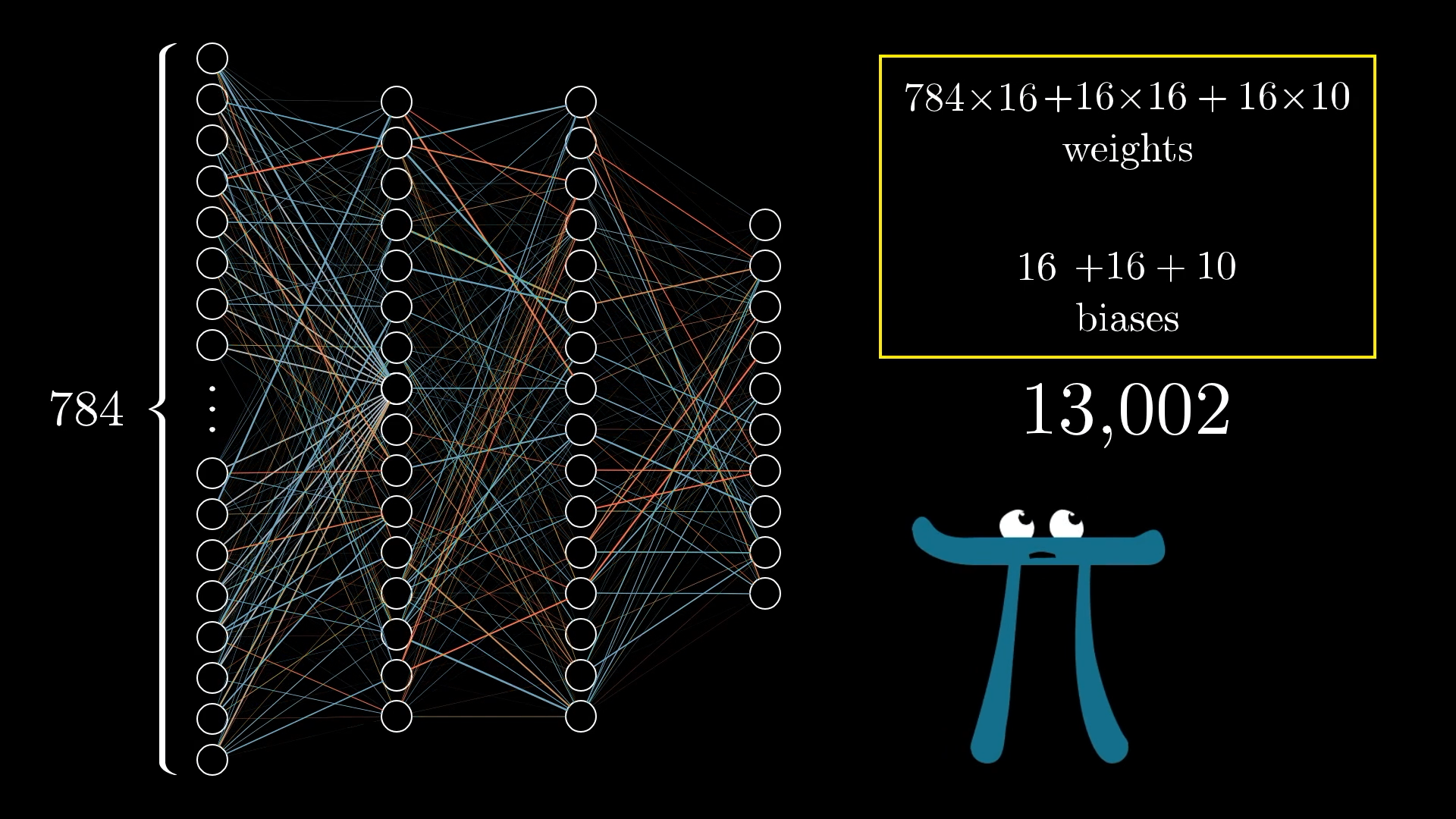
📊 The Numbers
Weight Breakdown:
- Input to Hidden 1: 784×16 = 12,544 weights
- Hidden 1 to Hidden 2: 16×16 = 256 weights
- Hidden 2 to Output: 16×10 = 160 weights
- Plus biases: 16+16+10 = 42
🧮 The Weighted Sum: Core Calculation
Every neuron in a hidden or output layer performs the same fundamental calculation:
Where:
- wᵢ = weight of connection i
- aᵢ = activation of neuron i in previous layer
- n = number of neurons in previous layer
🎯 What This Means
Each neuron is asking: "Based on the pattern of activations in the previous layer, and given my weights, how excited should I be?"
Part V
Activation Functions: The Squishification
The Problem: Unlimited Range

⚠️ The Challenge
Weighted Sum Problems:
- Can be any number: -1000, +500, etc.
- Our neurons need values 0.0-1.0
- Need smooth, differentiable function
- Should preserve relative ordering
🎯 Requirements
We need a function that smoothly maps any real number to our desired 0-1 range, while preserving the relative magnitudes.
The Sigmoid Function: Perfect Solution
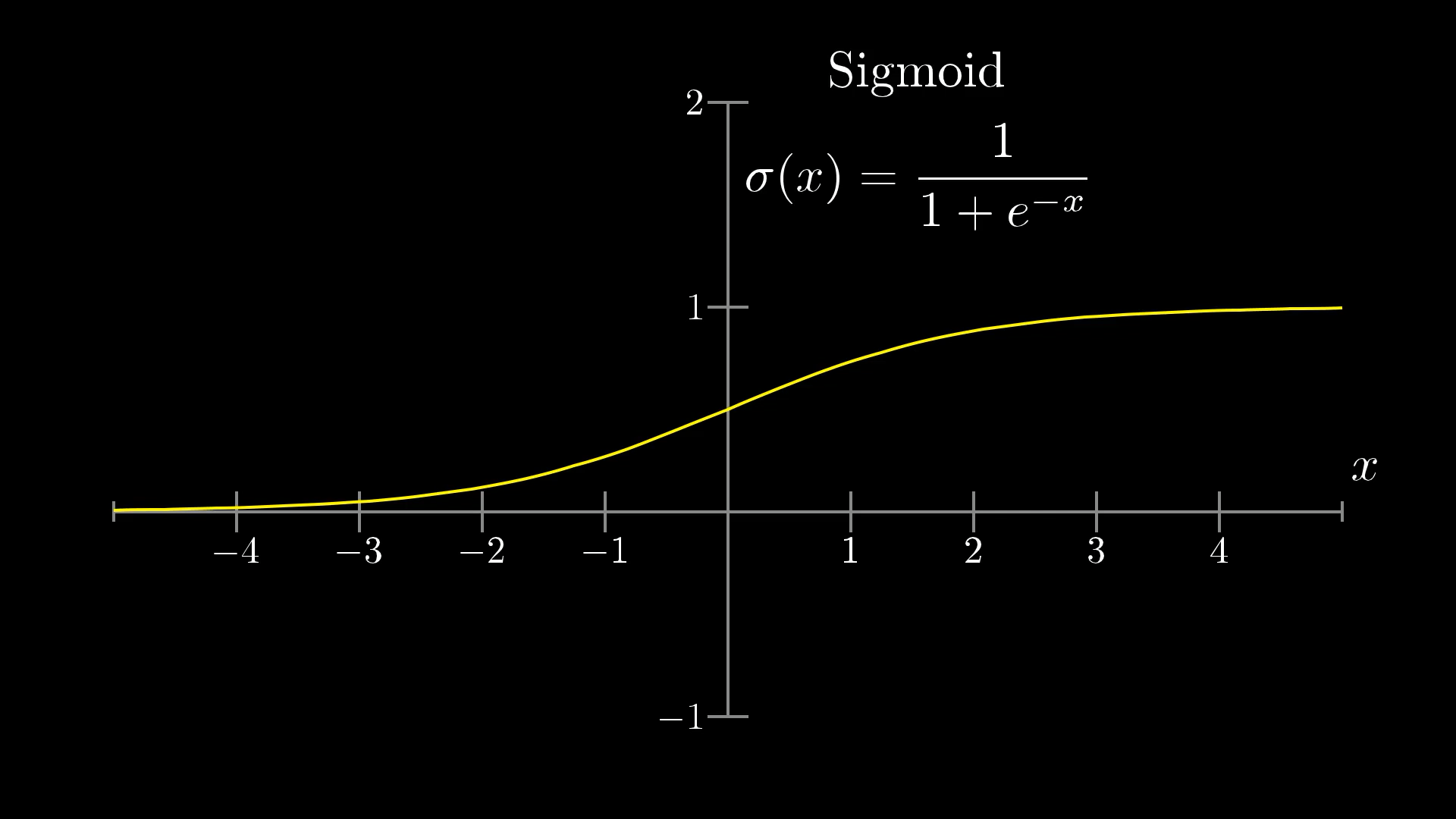
📈 Sigmoid Properties
Mathematical Definition:
Key Properties:
- Range: (0, 1) - perfect for our needs!
- Smooth and continuous
- Differentiable everywhere
- S-shaped curve
- σ(0) = 0.5 (midpoint)
Bias: Fine-Tuning Activation
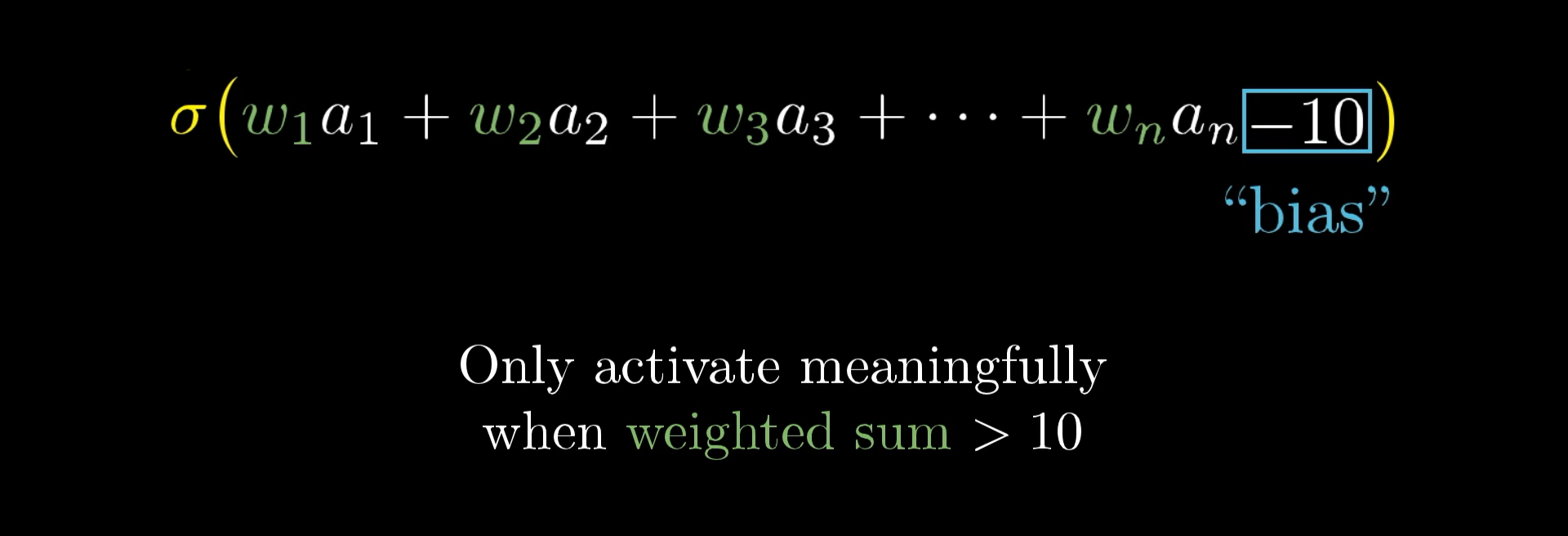
⚙️ The Role of Bias
Problem: What if we don't want the neuron to activate when weighted_sum > 0?
Solution: Add a bias term!
Bias Effects:
- Negative bias: Harder to activate
- Positive bias: Easier to activate
- Zero bias: Activates at weighted_sum = 0
🎯 Control Mechanism
Bias lets us control exactly when each neuron should "fire"!
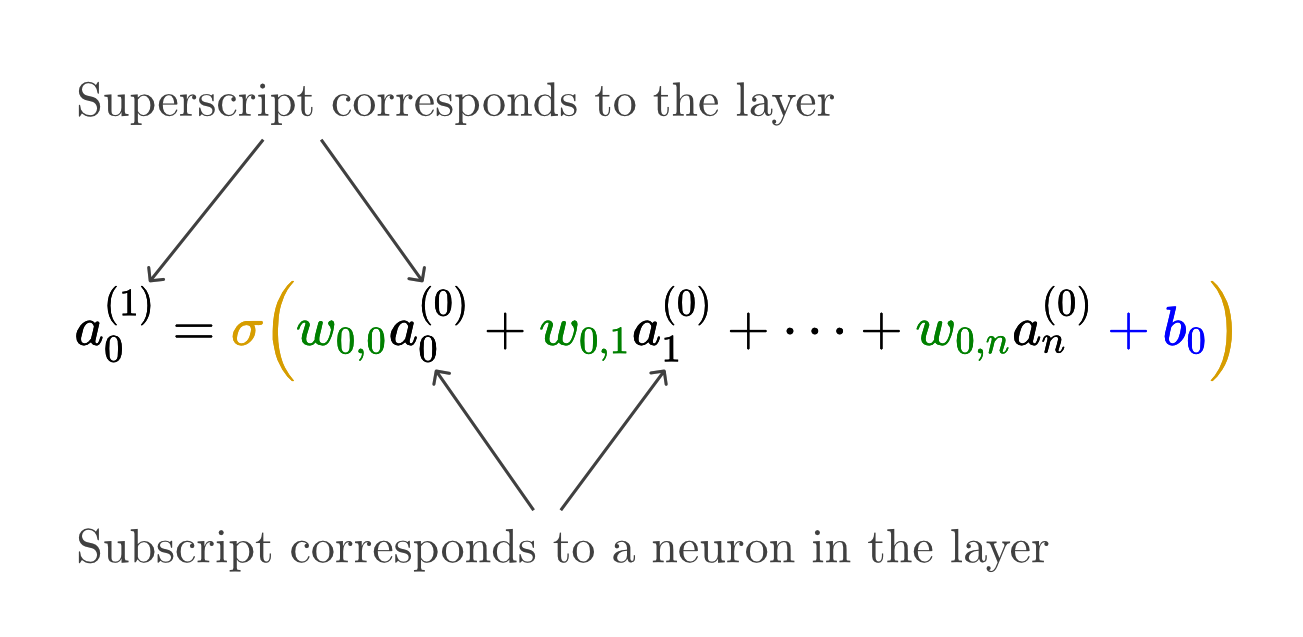
🧮 The Complete Neuron Formula
Now we can write the complete formula for any neuron's activation:
Where:
- aⱼ = activation of neuron j in current layer
- wᵢⱼ = weight from neuron i (prev layer) to neuron j (current layer)
- aᵢ = activation of neuron i in previous layer
- bⱼ = bias of neuron j
- σ = sigmoid function
🎉 This is it!
This single formula describes how every neuron in every hidden and output layer computes its activation. The entire network is just this formula applied thousands of times!
Part VI
Matrix Mathematics: Elegant Notation
Matrix Magic: Computing All Neurons at Once
🧮 Matrix Power
Instead of computing each neuron individually, we can compute ALL neurons in a layer simultaneously using matrix operations!
Notation Guide:
- a⁽ˡ⁾: Activations of layer l
- W⁽ˡ⁾: Weight matrix from layer l to l+1
- b⁽ˡ⁾: Bias vector for layer l+1
- σ: Applied element-wise
📐 Matrix Dimensions: Getting the Math Right
Understanding matrix dimensions is crucial for implementing neural networks:
📊 Dimension Analysis
For a layer with n input neurons and m output neurons:
- Weight matrix W: m × n (rows = outputs, cols = inputs)
- Input activations a: n × 1 (column vector)
- Bias vector b: m × 1 (column vector)
- Output activations: m × 1 (column vector)
Why This Matters:
- Enables vectorized computation (much faster!)
- Libraries like NumPy/TensorFlow optimize matrix operations
- Makes code cleaner and more readable
- Essential for implementing backpropagation (next lesson!)
Part VII
The Big Picture: Understanding the Complete System
🔧 The Network as a Function
Let's step back and see the forest for the trees:
For our digit recognizer:
- Input: 784 numbers (pixel values)
- Output: 10 numbers (digit probabilities)
- Parameters: 13,002 weights and biases
- Operations: Matrix multiplications and sigmoid applications
🤯 Mind-Blowing Realization
This "function" can recognize handwritten digits better than most humans, yet it's just arithmetic operations applied in sequence!
Sophisticated Solution for the Complexity
🔥 The Complexity/ Challange
- 13,002 parameters to tune
- Thousands of multiplication operations
- Non-linear transformations at each layer
- Intricate interaction patterns
- Emergent intelligent behavior
✨ The Solution
- Every neuron follows the same simple rule
- Just weighted sums and sigmoid functions
- Beautiful mathematical structure
- Scalable to any size network
- Universal approximation capability
🔮 How network Learn?
We now understand the structure and mathematics, but the biggest question remains:
What we know so far:
- ✅ What neurons are and how they work
- ✅ How layers organize to solve complex problems
- ✅ How weights and biases control behavior
- ✅ How activation functions keep values in range
- ✅ How matrix math makes it all efficient
What we still need to learn:
- ❓ How do we find the right weight values?
- ❓ What does "learning from examples" actually mean?
- ❓ How do we measure if our network is improving?
- ❓ How do we automatically adjust thousands of parameters?
🎯 Next Topic
The learning process involves gradient descent and backpropagation - elegant mathematical techniques that automatically adjust all 13,002 parameters to minimize prediction errors!