2^(2^10) = 2^1024 possible functions
For just 10 yes/no features!
That's more than the number of atoms
in the observable universe!
Think of machine learning like teaching a child to recognize different animals. Just as a child learns to distinguish between cats and dogs by seeing many examples, machine learning algorithms learn patterns from data to make predictions about new, unseen information.

Imagine you're looking for a house in a city. The hypothesis space is like all the possible houses that exist in that city - every single building that could potentially be your new home.

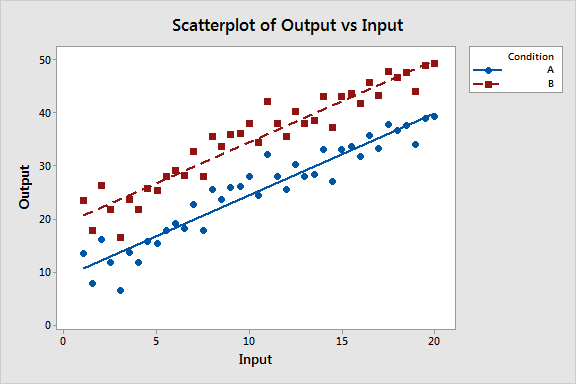
Hypothesis Space: All possible straight lines (y = mx + b)
Each Hypothesis: One specific line with particular slope and intercept
Goal: Find the line that best fits our data points
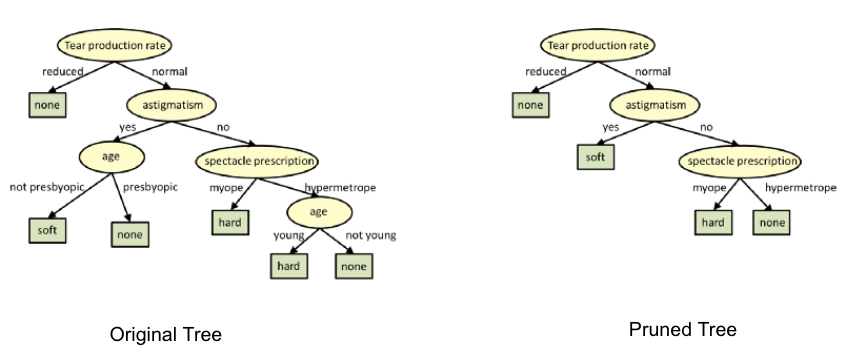
Hypothesis Space: All possible decision trees we can build
Each Hypothesis: One specific tree structure with particular splits
Goal: Find the tree that makes the most accurate predictions
Inductive bias is like having a wise mentor who gives you helpful assumptions and guidelines to narrow down your search.
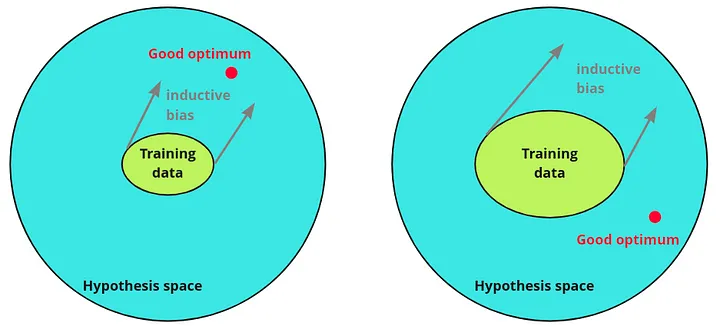
Think of it as:


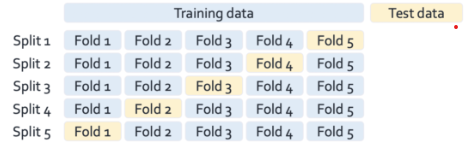
Imagine you're a teacher grading students. You wouldn't just look at homework performance; you'd give them tests on new problems to see if they truly understand the material.

Similarly, we need to test our ML models on new, unseen data to measure their real-world performance.

The foundation for understanding all classification metrics

Precision: "When we said someone has the disease, how often were we right?"
Critical when false positives lead to unnecessary surgery, anxiety, or treatments.

Recall: "Of all people who actually have the disease, how many did we catch?"
Critical when missing a disease could be life-threatening.
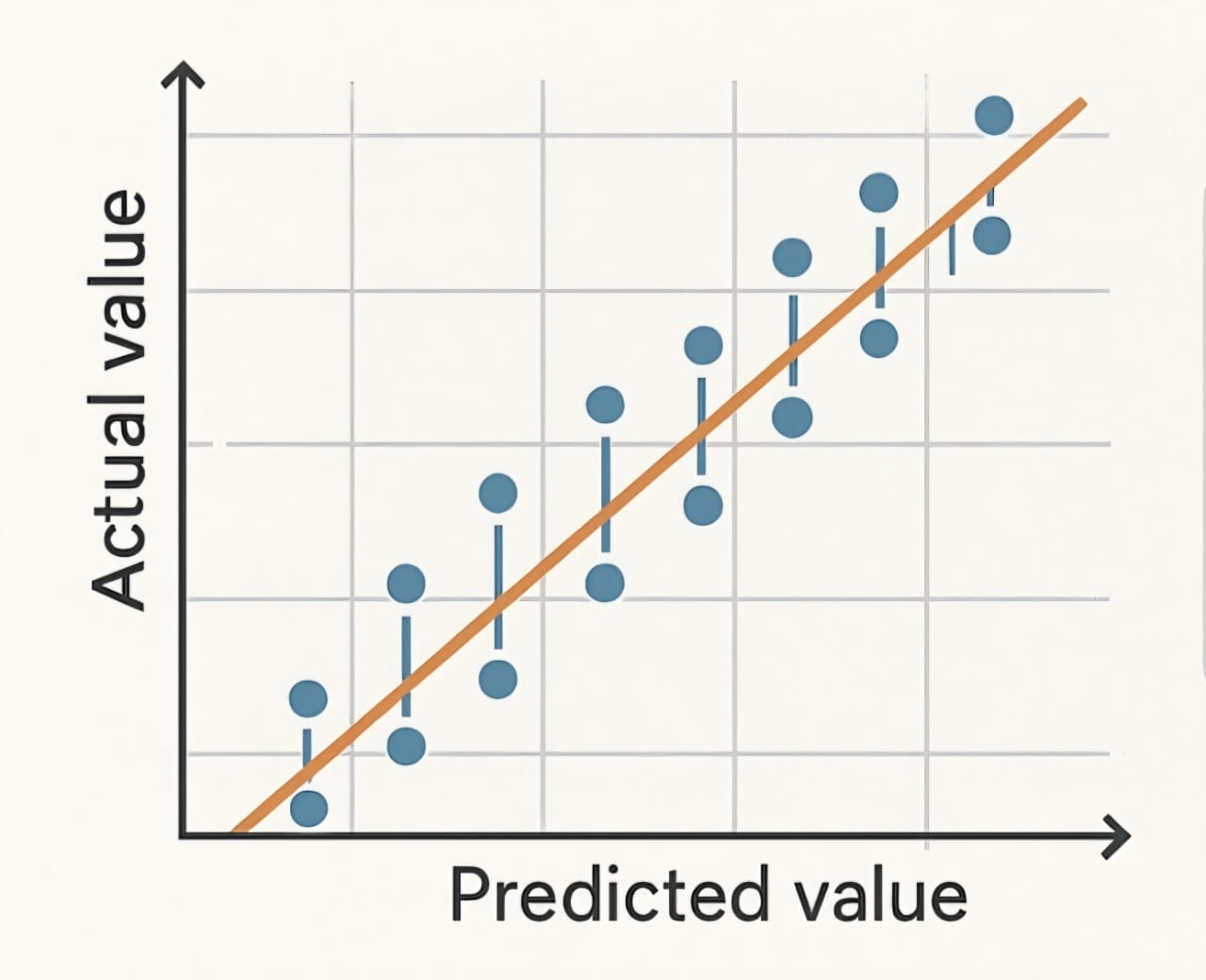
When predicting continuous values like house prices or temperatures, we need different metrics:
Studying only one practice test vs. comprehensive preparation